AlphaDDA: strategies for adjusting the playing strength of a fully
Por um escritor misterioso
Last updated 12 abril 2025
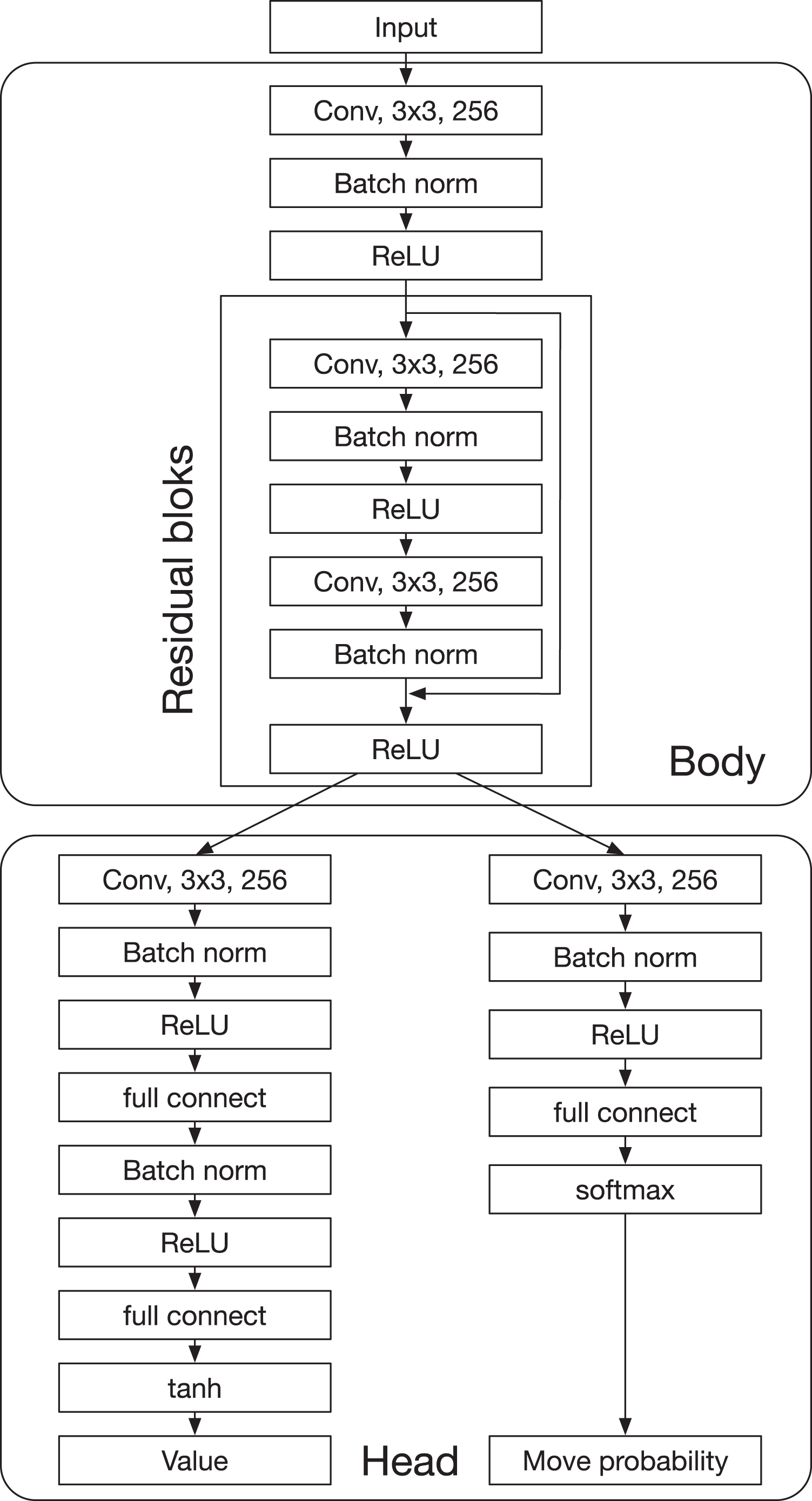
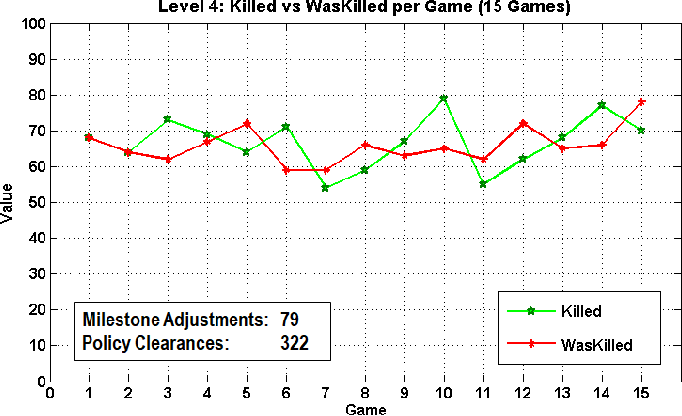
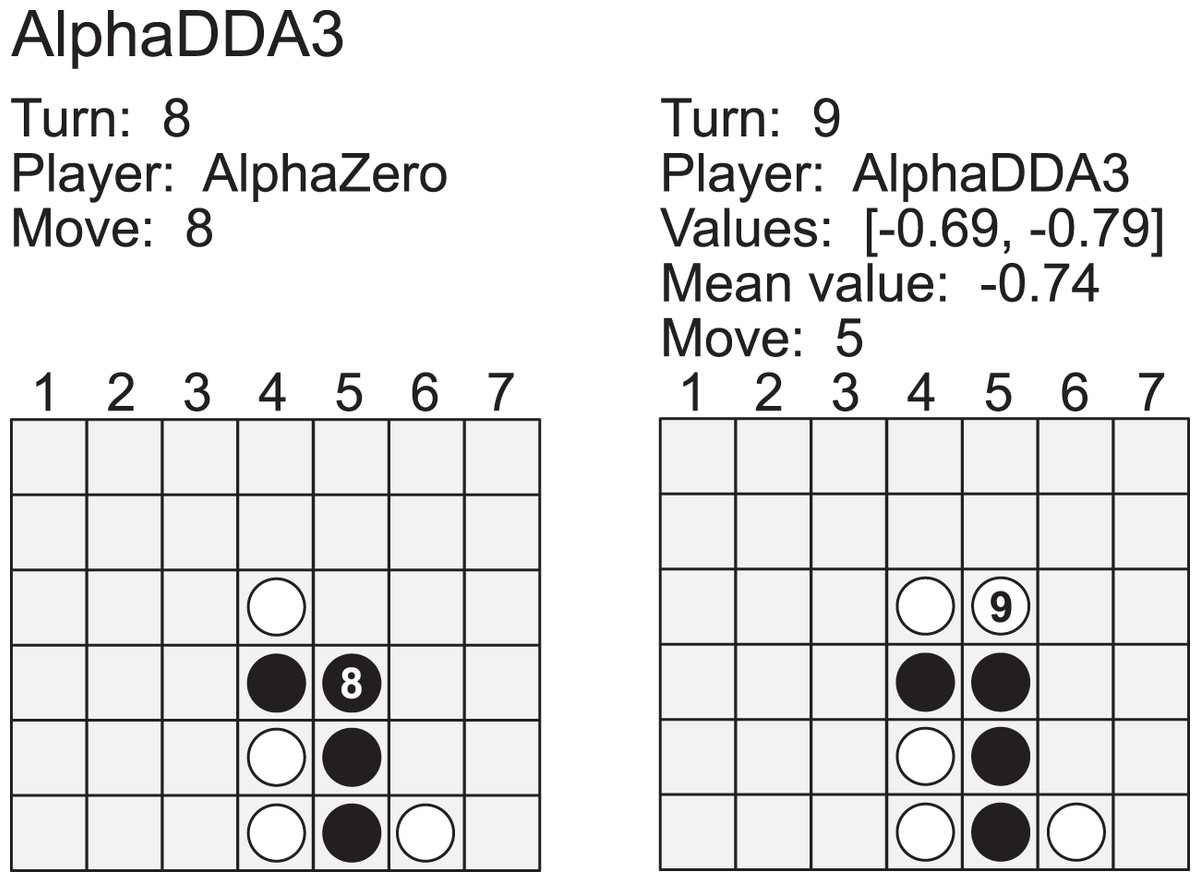
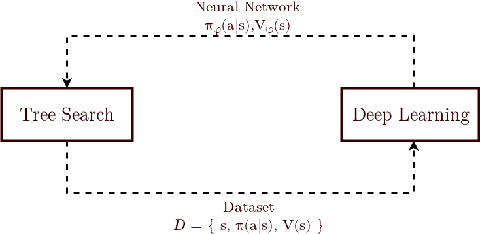
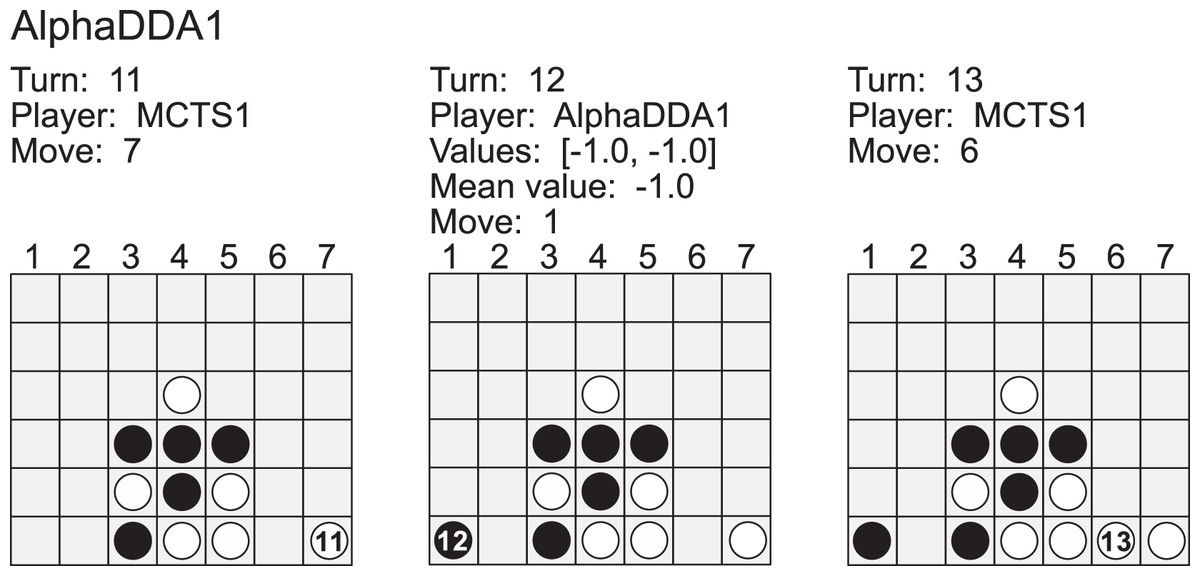
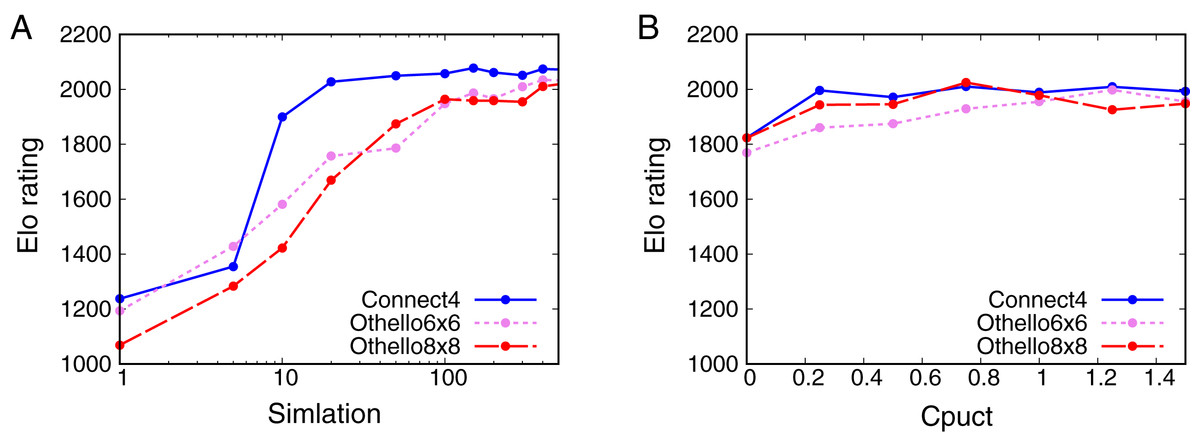
Artificial intelligence (AI) has achieved superhuman performance in board games such as Go, chess, and Othello (Reversi). In other words, the AI system surpasses the level of a strong human expert player in such games. In this context, it is difficult for a human player to enjoy playing the games with the AI. To keep human players entertained and immersed in a game, the AI is required to dynamically balance its skill with that of the human player. To address this issue, we propose AlphaDDA, an AlphaZero-based AI with dynamic difficulty adjustment (DDA). AlphaDDA consists of a deep neural network (DNN) and a Monte Carlo tree search, as in AlphaZero. AlphaDDA learns and plays a game the same way as AlphaZero, but can change its skills. AlphaDDA estimates the value of the game state from only the board state using the DNN. AlphaDDA changes a parameter dominantly controlling its skills according to the estimated value. Consequently, AlphaDDA adjusts its skills according to a game state. AlphaDDA can adjust its skill using only the state of a game without any prior knowledge regarding an opponent. In this study, AlphaDDA plays Connect4, Othello, and 6x6 Othello with other AI agents. Other AI agents are AlphaZero, Monte Carlo tree search, the minimax algorithm, and a random player. This study shows that AlphaDDA can balance its skill with that of the other AI agents, except for a random player. AlphaDDA can weaken itself according to the estimated value. However, AlphaDDA beats the random player because AlphaDDA is stronger than a random player even if AlphaDDA weakens itself to the limit. The DDA ability of AlphaDDA is based on an accurate estimation of the value from the state of a game. We believe that the AlphaDDA approach for DDA can be used for any game AI system if the DNN can accurately estimate the value of the game state and we know a parameter controlling the skills of the AI system.
PDF] Skilled Experience Catalogue: A Skill-Balancing Mechanism for Non- Player Characters using Reinforcement Learning
An overview of Skilled Experience Catalogue.
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]

Game Changer: AlphaZero's Groundbreaking Chess Strategies and the Promise of AI

arxiv-sanity
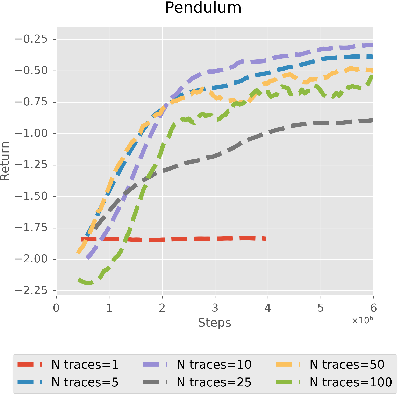
PDF] A0C: Alpha Zero in Continuous Action Space
PDF] A0C: Alpha Zero in Continuous Action Space
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
Recomendado para você
-
 Acquisition of chess knowledge in AlphaZero12 abril 2025
Acquisition of chess knowledge in AlphaZero12 abril 2025 -
 AlphaZero: Reactions From Top GMs, Stockfish Author : r/chess12 abril 2025
AlphaZero: Reactions From Top GMs, Stockfish Author : r/chess12 abril 2025 -
Alphazero Chess Download PNG - Google-Keresés12 abril 2025
-
 🔵 AlphaZero Plays Connect 412 abril 2025
🔵 AlphaZero Plays Connect 412 abril 2025 -
GitHub - Kruszylo/gomoku-bot: A replica of the AlphaZero12 abril 2025
-
 GitHub - blaisewang/Othello-Zero: Othello game with AlphaZero12 abril 2025
GitHub - blaisewang/Othello-Zero: Othello game with AlphaZero12 abril 2025 -
 最强通用棋类AI,AlphaZero强化学习算法解读- 深度强化学习实验室12 abril 2025
最强通用棋类AI,AlphaZero强化学习算法解读- 深度强化学习实验室12 abril 2025 -
 动手实现并行版AlphaZero · hijkzzz/alpha-zero-gomoku Wiki · GitHub12 abril 2025
动手实现并行版AlphaZero · hijkzzz/alpha-zero-gomoku Wiki · GitHub12 abril 2025 -
 Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J12 abril 2025
Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J12 abril 2025 -
 Leela Zero( A Neural Network engine similar to Alpha Zero) - Chess12 abril 2025
Leela Zero( A Neural Network engine similar to Alpha Zero) - Chess12 abril 2025
você pode gostar
-
 Spy Game (2001) Original One-Sheet Teaser Movie Poster - Original Film Art - Vintage Movie Posters12 abril 2025
Spy Game (2001) Original One-Sheet Teaser Movie Poster - Original Film Art - Vintage Movie Posters12 abril 2025 -
Would you fire your secretary, for a free Siri-like, virtual assistant ?12 abril 2025
-
 Street Fighter X Tekken may soon return to PC after being rendered12 abril 2025
Street Fighter X Tekken may soon return to PC after being rendered12 abril 2025 -
 Banpresto Dragon Ball Super 5.1 Super Saiyan 2 Goku Figure, SCultures Big Budoukai 6, Volume 4 : Toys & Games12 abril 2025
Banpresto Dragon Ball Super 5.1 Super Saiyan 2 Goku Figure, SCultures Big Budoukai 6, Volume 4 : Toys & Games12 abril 2025 -
 English Opening, King's English Variation, Reversed Closed Sicilian A2512 abril 2025
English Opening, King's English Variation, Reversed Closed Sicilian A2512 abril 2025 -
 Dragon Age: Origins – Awakening/(Keep Adding Shit to the Title)12 abril 2025
Dragon Age: Origins – Awakening/(Keep Adding Shit to the Title)12 abril 2025 -
 Wildgaming – Creating Games Players Love to Play12 abril 2025
Wildgaming – Creating Games Players Love to Play12 abril 2025 -
 Bayonetta STEAM digital for Windows, Steam Deck12 abril 2025
Bayonetta STEAM digital for Windows, Steam Deck12 abril 2025 -
 Sarah no BBB21: Faça o quiz e descubra se você seria espiã(o) como12 abril 2025
Sarah no BBB21: Faça o quiz e descubra se você seria espiã(o) como12 abril 2025 -
 GLEE CAST songs and albums full Official Chart history12 abril 2025
GLEE CAST songs and albums full Official Chart history12 abril 2025
