AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]
Por um escritor misterioso
Last updated 11 abril 2025
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-5-full.png)
Artificial intelligence (AI) has achieved superhuman performance in board games such as Go, chess, and Othello (Reversi). In other words, the AI system surpasses the level of a strong human expert player in such games. In this context, it is difficult for a human player to enjoy playing the games with the AI. To keep human players entertained and immersed in a game, the AI is required to dynamically balance its skill with that of the human player. To address this issue, we propose AlphaDDA, an AlphaZero-based AI with dynamic difficulty adjustment (DDA). AlphaDDA consists of a deep neural network (DNN) and a Monte Carlo tree search, as in AlphaZero. AlphaDDA learns and plays a game the same way as AlphaZero, but can change its skills. AlphaDDA estimates the value of the game state from only the board state using the DNN. AlphaDDA changes a parameter dominantly controlling its skills according to the estimated value. Consequently, AlphaDDA adjusts its skills according to a game state. AlphaDDA can adjust its skill using only the state of a game without any prior knowledge regarding an opponent. In this study, AlphaDDA plays Connect4, Othello, and 6x6 Othello with other AI agents. Other AI agents are AlphaZero, Monte Carlo tree search, the minimax algorithm, and a random player. This study shows that AlphaDDA can balance its skill with that of the other AI agents, except for a random player. AlphaDDA can weaken itself according to the estimated value. However, AlphaDDA beats the random player because AlphaDDA is stronger than a random player even if AlphaDDA weakens itself to the limit. The DDA ability of AlphaDDA is based on an accurate estimation of the value from the state of a game. We believe that the AlphaDDA approach for DDA can be used for any game AI system if the DNN can accurately estimate the value of the game state and we know a parameter controlling the skills of the AI system.
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://journals.sagepub.com/cms/10.1177/13621688211004645/asset/images/large/10.1177_13621688211004645-fig1.jpeg)
Willingness to communicate in the L2 about meaningful photos
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://s3.amazonaws.com/peerj_prod_upload/images/profile/k%2Fa%2FblQbh_mYB8NB8upldO4mEg%3D%3D%2Fi200_642ffe9b7ccc33.72068827.jpeg)
PeerJ - Profile - Kazuhisa Fujita
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-1-full.png)
AlphaDDA: strategies for adjusting the playing strength of a fully
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-5-2x.jpg)
AlphaDDA: strategies for adjusting the playing strength of a fully
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-7-2x.jpg)
AlphaDDA: strategies for adjusting the playing strength of a fully
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](http://spikingneuron.net/ja/img/quantize.png)
研究概要
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://imgopt.infoq.com/fit-in/1200x2400/filters:quality(80)/filters:no_upscale()/articles/multi-armed-bandits-reinforcement-learning/en/resources/7image4-1588077752247.jpg)
Reinforcement Machine Learning for Effective Clinical Trials
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://d2pdyyx74uypu5.cloudfront.net/images/reward-recognition/contributor-levels/contributer-shield-silver.svg)
PeerJ - Profile - Yilun Shang
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://miro.medium.com/v2/resize:fit:1400/1*exj_eqNM2Zi2wXmVwkHGcw.png)
Reinforcement Learning with Multi Arm Bandit (Part 2)
Recomendado para você
-
Is any human capable of beating AlphaZero in chess or go? - Quora11 abril 2025
-
 LcZero ELO Rating List Estimates (Includes: AlphaZero, All Stockfish version releases, Stockfish Variants, Lc0 CUDA, and TCEC Div1+DivP Engines)11 abril 2025
LcZero ELO Rating List Estimates (Includes: AlphaZero, All Stockfish version releases, Stockfish Variants, Lc0 CUDA, and TCEC Div1+DivP Engines)11 abril 2025 -
![AlphaZero vs Stockfish 8 Scaling Recreation [50% Complete] by Cscuile](https://groups.google.com/group/lczero/attach/3a45501fba376/Leela%20vs%20Stockfish%20Scaling.PNG?part=0.2&view=1) AlphaZero vs Stockfish 8 Scaling Recreation [50% Complete] by Cscuile11 abril 2025
AlphaZero vs Stockfish 8 Scaling Recreation [50% Complete] by Cscuile11 abril 2025 -
Has the Alpha Zero chess program been made to play the Evans Gambit against itself, in an attempt to discover whether that gambit, with best play, is theoretically sound or whether White11 abril 2025
-
 8 Grandmasters Together Play against Alfazero (4000 elo), chess strategy, Alphazero vs GM11 abril 2025
8 Grandmasters Together Play against Alfazero (4000 elo), chess strategy, Alphazero vs GM11 abril 2025 -
 Legendary 4000 Elo Chess Battle !! Stockfish 15.1 Vs Alpha Zero, Stockfish 15.1, Gothamchess11 abril 2025
Legendary 4000 Elo Chess Battle !! Stockfish 15.1 Vs Alpha Zero, Stockfish 15.1, Gothamchess11 abril 2025 -
 What is the theoretical Elo of AlphaGo? - Quora11 abril 2025
What is the theoretical Elo of AlphaGo? - Quora11 abril 2025 -
 7000 ELO PERFORMANCE OF Stockfish and AlphaZero | Stockfish Vs AlphaZero |_哔哩哔哩_bilibili11 abril 2025
7000 ELO PERFORMANCE OF Stockfish and AlphaZero | Stockfish Vs AlphaZero |_哔哩哔哩_bilibili11 abril 2025 -
 Stockfish - 5000 ELO Chess Brilliance: The Stockfish vs. AlphaZero Showdown_桌游棋牌热门视频11 abril 2025
Stockfish - 5000 ELO Chess Brilliance: The Stockfish vs. AlphaZero Showdown_桌游棋牌热门视频11 abril 2025 -
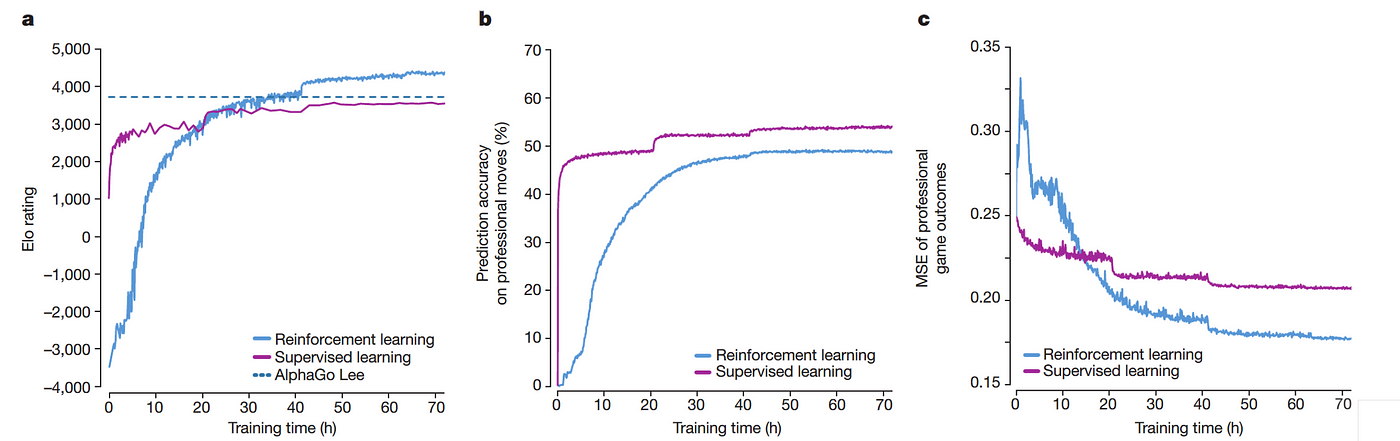 How DeepMind's AlphaGo Became the World's Top Go Player, by Andre Ye11 abril 2025
How DeepMind's AlphaGo Became the World's Top Go Player, by Andre Ye11 abril 2025
você pode gostar
-
Buy Minecraft: Deluxe Collection11 abril 2025
-
![Взлом на PvZ2 абсолютно на Всё (6.8.1) [ПАК ВЗЛОМОВ]](https://i.ytimg.com/vi/2DY6WDo40t0/maxresdefault.jpg) Взлом на PvZ2 абсолютно на Всё (6.8.1) [ПАК ВЗЛОМОВ]11 abril 2025
Взлом на PvZ2 абсолютно на Всё (6.8.1) [ПАК ВЗЛОМОВ]11 abril 2025 -
![Ipad Mini/mini 2 Case Slim [ultra Fit] Crunchyroll Yama No Susume Protective Case Cover : : Computers & Accessories](https://m.media-amazon.com/images/I/41H-JjZkMmL.jpg) Ipad Mini/mini 2 Case Slim [ultra Fit] Crunchyroll Yama No Susume Protective Case Cover : : Computers & Accessories11 abril 2025
Ipad Mini/mini 2 Case Slim [ultra Fit] Crunchyroll Yama No Susume Protective Case Cover : : Computers & Accessories11 abril 2025 -
Asdasdasdas Minecraft Skins11 abril 2025
-
 Tabuleiro xadrez magnético 3323M XA-02 25cm - PENA VERDE SHOP11 abril 2025
Tabuleiro xadrez magnético 3323M XA-02 25cm - PENA VERDE SHOP11 abril 2025 -
As risadas mais engraçadas do Brail!😂 #meme #memes #memebrasil11 abril 2025
-
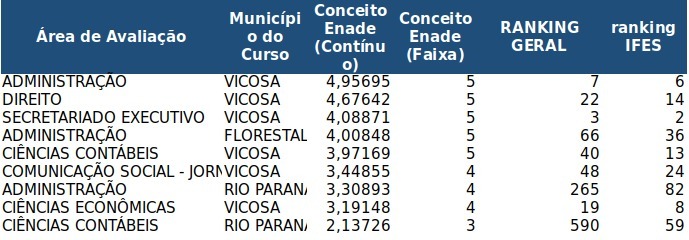 ENADE- Cursos de Administração e Contabilidade – NOTA MÁXIMA.11 abril 2025
ENADE- Cursos de Administração e Contabilidade – NOTA MÁXIMA.11 abril 2025 -
 Dean norris and aaron paul hi-res stock photography and images - Alamy11 abril 2025
Dean norris and aaron paul hi-res stock photography and images - Alamy11 abril 2025 -
 Cuáles son las fortalezas y debilidades de los Pokémon de tipo11 abril 2025
Cuáles son las fortalezas y debilidades de los Pokémon de tipo11 abril 2025 -
 Duck Life 9 - A new world!11 abril 2025
Duck Life 9 - A new world!11 abril 2025

