Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play
Por um escritor misterioso
Last updated 12 abril 2025
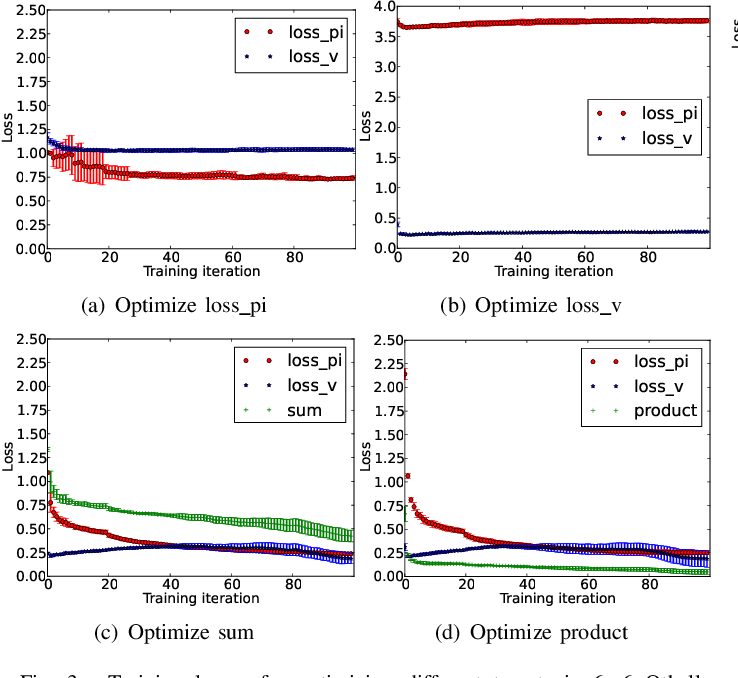
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.
MuZero Intuition

AlphaGo Zero – How and Why it Works – Tim Wheeler
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript

Representation Matters: The Game of Chess Poses a Challenge to

Reimagining Chess with AlphaZero, February 2022

AlphaZero: A General Reinforcement Learning Algorithm that Masters
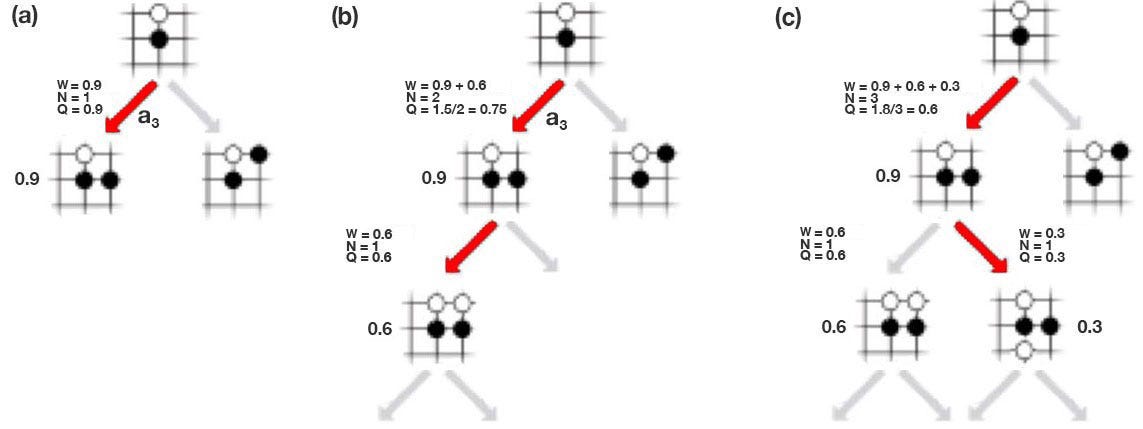
AlphaGo Zero — a game changer. (How it works?)
The loss function · Issue #39 · Zeta36/chess-alpha-zero · GitHub

A general reinforcement learning algorithm that masters chess
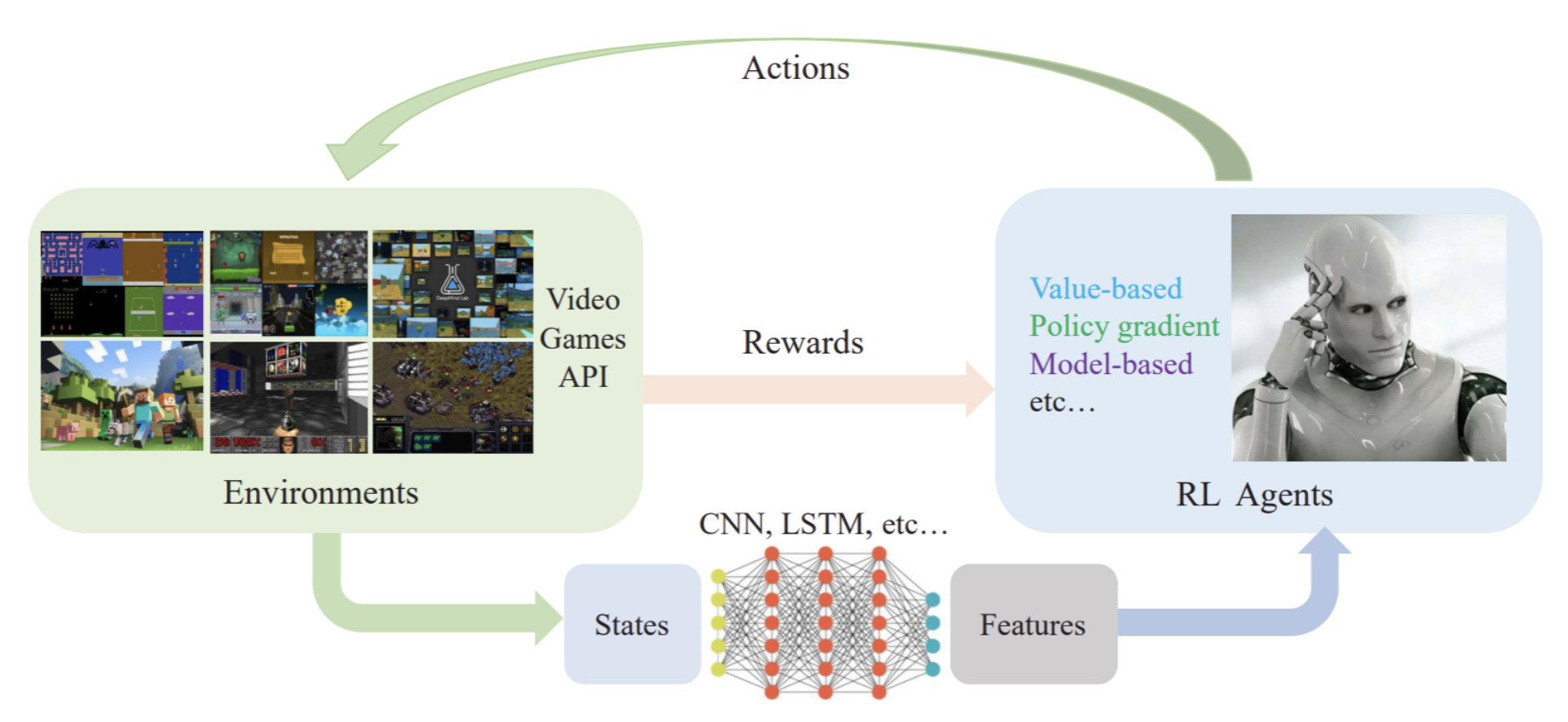
The Data Problem III: Machine Learning Without Data - Synthesis AI

Value targets in off-policy AlphaZero: a new greedy backup
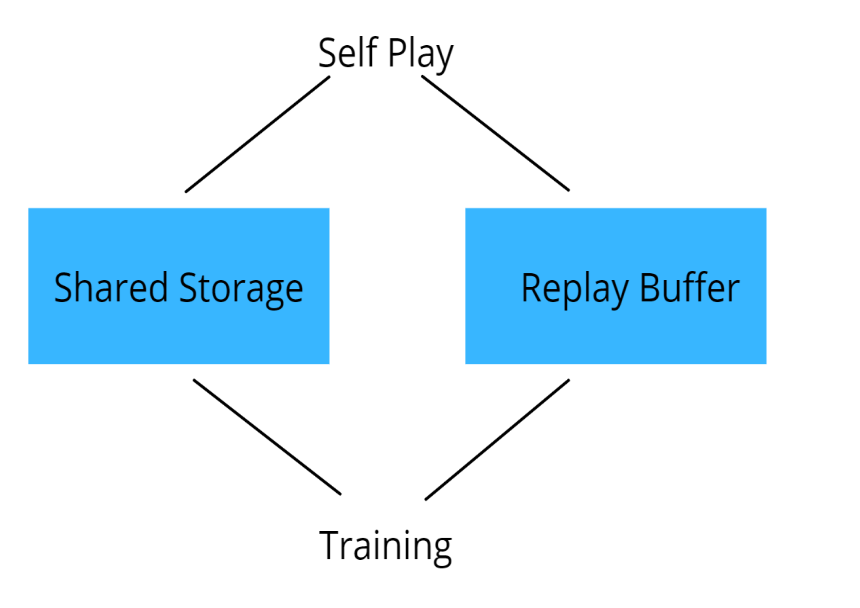
Superhuman Algorithm: MuZero Explained, by Ape Gainz
Recomendado para você
-
 Stockfish (chess) - Wikipedia12 abril 2025
Stockfish (chess) - Wikipedia12 abril 2025 -
 Chess's New Best Player Is A Fearless, Swashbuckling Algorithm12 abril 2025
Chess's New Best Player Is A Fearless, Swashbuckling Algorithm12 abril 2025 -
 Simple Alpha Zero12 abril 2025
Simple Alpha Zero12 abril 2025 -
 4050 Elo Rating Performance of AlphaZero, AlphaZero Vs AlphaZero, Chess com, Gotham chess12 abril 2025
4050 Elo Rating Performance of AlphaZero, AlphaZero Vs AlphaZero, Chess com, Gotham chess12 abril 2025 -
Empirical evaluation of AlphaGo Zero. a Performance of self-play12 abril 2025
-
 Why DeepMind AlphaGo Zero is a game changer for AI research12 abril 2025
Why DeepMind AlphaGo Zero is a game changer for AI research12 abril 2025 -
Comparison of neural network architectures in AlphaGo Zero and AlphaGo12 abril 2025
-
 AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community12 abril 2025
AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community12 abril 2025 -
 Training AlphaZero for 700,000 steps. Elo ratings were computed from12 abril 2025
Training AlphaZero for 700,000 steps. Elo ratings were computed from12 abril 2025 -
 A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play12 abril 2025
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play12 abril 2025
você pode gostar
-
 Download Dragon Ball Fighterz For Android Apk Obb12 abril 2025
Download Dragon Ball Fighterz For Android Apk Obb12 abril 2025 -
 Pokémon GO' Pokémons Capazes de Mega-evoluir12 abril 2025
Pokémon GO' Pokémons Capazes de Mega-evoluir12 abril 2025 -
 Best two-player Switch games that let you team up with a friend or12 abril 2025
Best two-player Switch games that let you team up with a friend or12 abril 2025 -
 Elomar Figueira Melo12 abril 2025
Elomar Figueira Melo12 abril 2025 -
 quebra-cabeça forma - Jogos quebra-cabeça Placa forma madeira - Brinquedo sensorial quebra-cabeça formas com formas geométricas Montessori Brinquedos12 abril 2025
quebra-cabeça forma - Jogos quebra-cabeça Placa forma madeira - Brinquedo sensorial quebra-cabeça formas com formas geométricas Montessori Brinquedos12 abril 2025 -
 Need for Speed Unbound on Steam Unlocked Version Free Download12 abril 2025
Need for Speed Unbound on Steam Unlocked Version Free Download12 abril 2025 -
 Path clear for Arjun, Pragg, Gukesh to become next world champ: Anand12 abril 2025
Path clear for Arjun, Pragg, Gukesh to become next world champ: Anand12 abril 2025 -
 Stop the Rumbling! Attack on Titan Final Season THE FINAL CHAPTERS Special 112 abril 2025
Stop the Rumbling! Attack on Titan Final Season THE FINAL CHAPTERS Special 112 abril 2025 -
 Arthur Petry em 2023 Podcast, Caras, Arthur petry12 abril 2025
Arthur Petry em 2023 Podcast, Caras, Arthur petry12 abril 2025 -
 Steam Deck Gameplay - Watch Dogs - SteamOS12 abril 2025
Steam Deck Gameplay - Watch Dogs - SteamOS12 abril 2025