PDF] Mastering Chess and Shogi by Self-Play with a General
Por um escritor misterioso
Last updated 12 abril 2025
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/7-Figure2-1.png)
This paper generalises the approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains, and convincingly defeated a world-champion program in each case. The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://upload.wikimedia.org/wikipedia/commons/thumb/5/52/Chess_Programming.svg/800px-Chess_Programming.svg.png)
AlphaZero - Wikipedia
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://www.researchgate.net/publication/343568113/figure/fig4/AS:923185167994883@1597115904708/Human-vs-Machine-in-Live-Play-with-Chess-Transformer-The-Colaboratory-notebook-includes_Q320.jpg)
PDF) The Chess Transformer: Mastering Play using Generative Language Models
What exactly makes the greatest players of all time, such as Magnus Carlsen, Bobby Fischer, and Garry Kasparov stand out from the rest? The basic
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://i.ytimg.com/vi/KVDoKNec9sQ/maxresdefault.jpg)
Mastering Chess Logic
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://slideplayer.com/slide/17602959/104/images/5/Presentations+of+interest.jpg)
AI & Games: The cases of Go, Chess and Shogi - ppt download
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/4c7028640e3470a73af84d22eafa78855931c70f/20-Figure2-1.png)
PDF] Giraffe: Using Deep Reinforcement Learning to Play Chess
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/cf39c819dc1352c3da52d4d4c7dd3a23fb933e97/5-Table1-1.png)
PDF] Mastering Terra Mystica: Applying Self-Play to Multi-agent Cooperative Board Games
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/071e11e5845e72466bb8fbdc617d45c4d83e7b0a/4-Figure5-1.png)
PDF] The Chess Transformer: Mastering Play using Generative Language Models
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://i.ytimg.com/vi/7-MborNxYWE/maxresdefault.jpg)
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://slideplayer.com/slide/17602959/104/images/4/Papers+of+interest.jpg)
AI & Games: The cases of Go, Chess and Shogi - ppt download
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://blog.acolyer.org/wp-content/uploads/2018/01/alphazero-table-s1.jpeg?w=520)
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/6-Table2-1.png)
PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://blog.acolyer.org/wp-content/uploads/2018/01/alphazero-table-2.jpeg?w=640)
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
Recomendado para você
-
 AlphaZero, Vladimir Kramnik and reinventing chess12 abril 2025
AlphaZero, Vladimir Kramnik and reinventing chess12 abril 2025 -
 AlphaZero - Wikipedia12 abril 2025
AlphaZero - Wikipedia12 abril 2025 -
 The Data Problem III: Machine Learning Without Data - Synthesis AI12 abril 2025
The Data Problem III: Machine Learning Without Data - Synthesis AI12 abril 2025 -
 AI Summary: Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search12 abril 2025
AI Summary: Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search12 abril 2025 -
 AlphaZero: DeepMind's New Chess AI12 abril 2025
AlphaZero: DeepMind's New Chess AI12 abril 2025 -
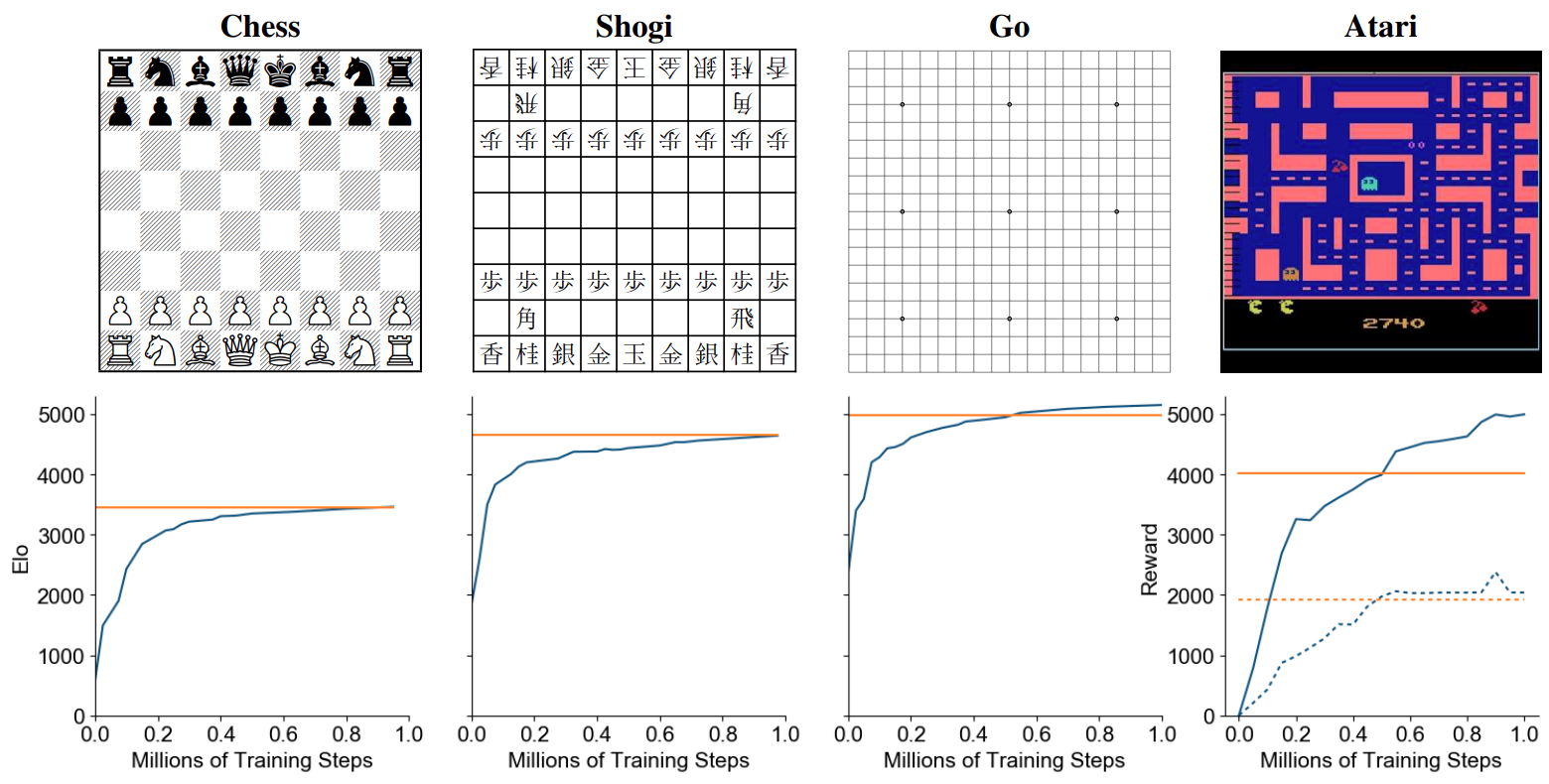 Simplifying MuZero in Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model — Andrew Silva12 abril 2025
Simplifying MuZero in Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model — Andrew Silva12 abril 2025 -
 Galactica. Galactica is a large language…, by karim, MLearning.ai12 abril 2025
Galactica. Galactica is a large language…, by karim, MLearning.ai12 abril 2025 -
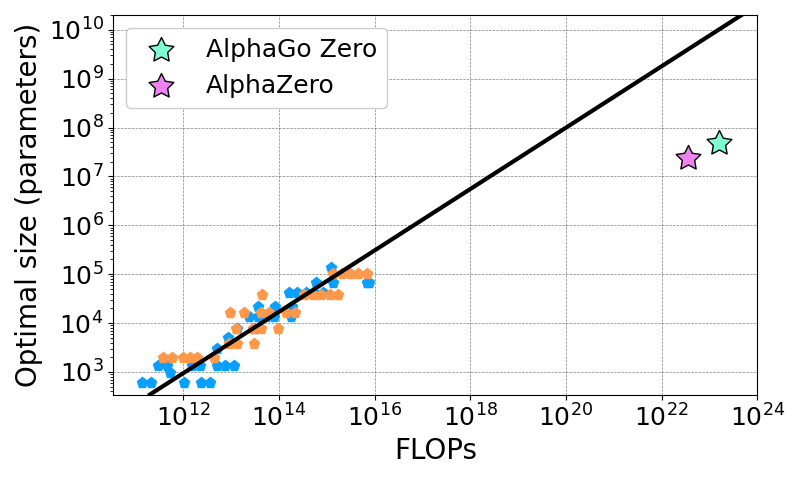 Oren Neumann on X: Do #RL models have scaling laws like LLMs? #AlphaZero does, and the laws imply SotA models were too small for their compute budgets. Check out our new paper12 abril 2025
Oren Neumann on X: Do #RL models have scaling laws like LLMs? #AlphaZero does, and the laws imply SotA models were too small for their compute budgets. Check out our new paper12 abril 2025 -
 Cammy street fighter alpha/ zero 3 Greeting Card by watolo12 abril 2025
Cammy street fighter alpha/ zero 3 Greeting Card by watolo12 abril 2025 -
 Mastering TicTacToe with AlphaZero12 abril 2025
Mastering TicTacToe with AlphaZero12 abril 2025
você pode gostar
-
 Lesbian Sex Scandals: Sexual Practices, Identities, and Politics: 9781560231189: Dawn Atkins: Books12 abril 2025
Lesbian Sex Scandals: Sexual Practices, Identities, and Politics: 9781560231189: Dawn Atkins: Books12 abril 2025 -
 Doramas com romances adultos - Thays M. de Lima12 abril 2025
Doramas com romances adultos - Thays M. de Lima12 abril 2025 -
 Shita - Apple Music12 abril 2025
Shita - Apple Music12 abril 2025 -
Baby Bella Doll House - Microsoft Apps12 abril 2025
-
 Projeto de extensão do Campus Mata Norte da UPE promove festival12 abril 2025
Projeto de extensão do Campus Mata Norte da UPE promove festival12 abril 2025 -
 Sans and Chara fighting Greeting Card for Sale by QuirkyTaco12 abril 2025
Sans and Chara fighting Greeting Card for Sale by QuirkyTaco12 abril 2025 -
 PatchBot for Garry's Mod12 abril 2025
PatchBot for Garry's Mod12 abril 2025 -
 Kousaka Sayaka Memorial Art Shirimochi ver. STRIKE THE BLOOD FINAL Order Production Limited, Goods / Accessories12 abril 2025
Kousaka Sayaka Memorial Art Shirimochi ver. STRIKE THE BLOOD FINAL Order Production Limited, Goods / Accessories12 abril 2025 -
fandom-artworks.tumblr.com - Tumbex12 abril 2025
-
 Immutable Eliminates Fees in zkEVM Gaming Solution + More News12 abril 2025
Immutable Eliminates Fees in zkEVM Gaming Solution + More News12 abril 2025

