XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 22 abril 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
Figure A2: Truncated distribution of usages per dataset in PWC

PDF] JaQuAD: Japanese Question Answering Dataset for Machine
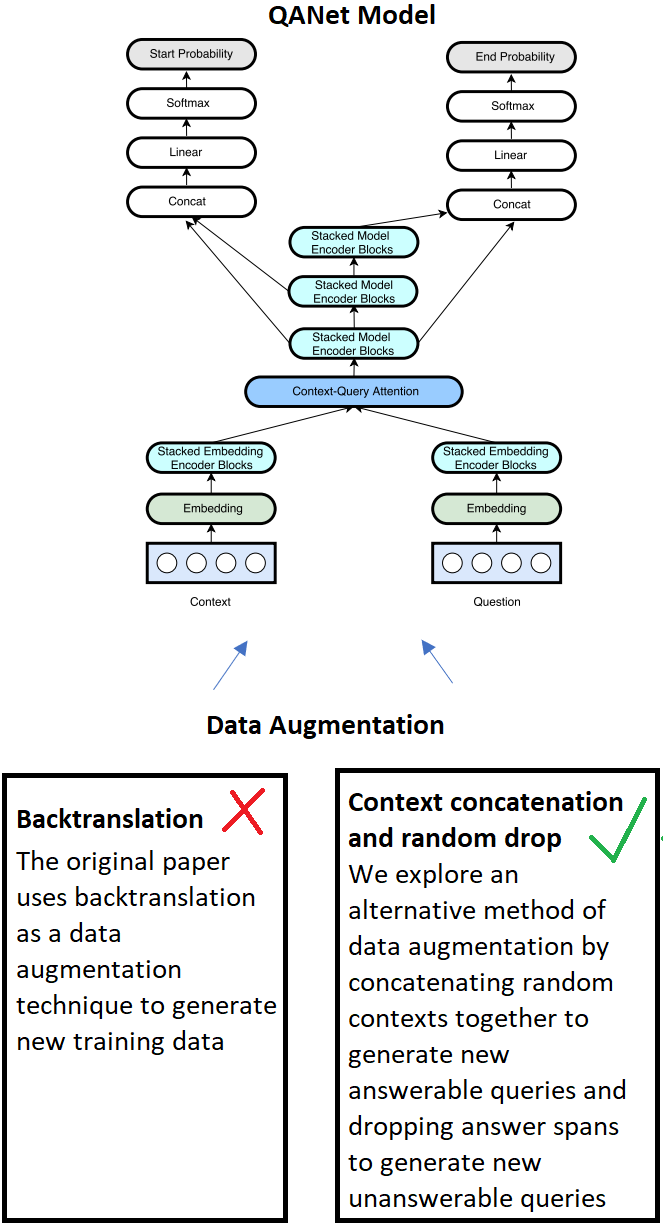
image171.png

How to Answer Questions with Machine Learning

MLQA Dataset Papers With Code
How to Build an Open-Domain Question Answering System?
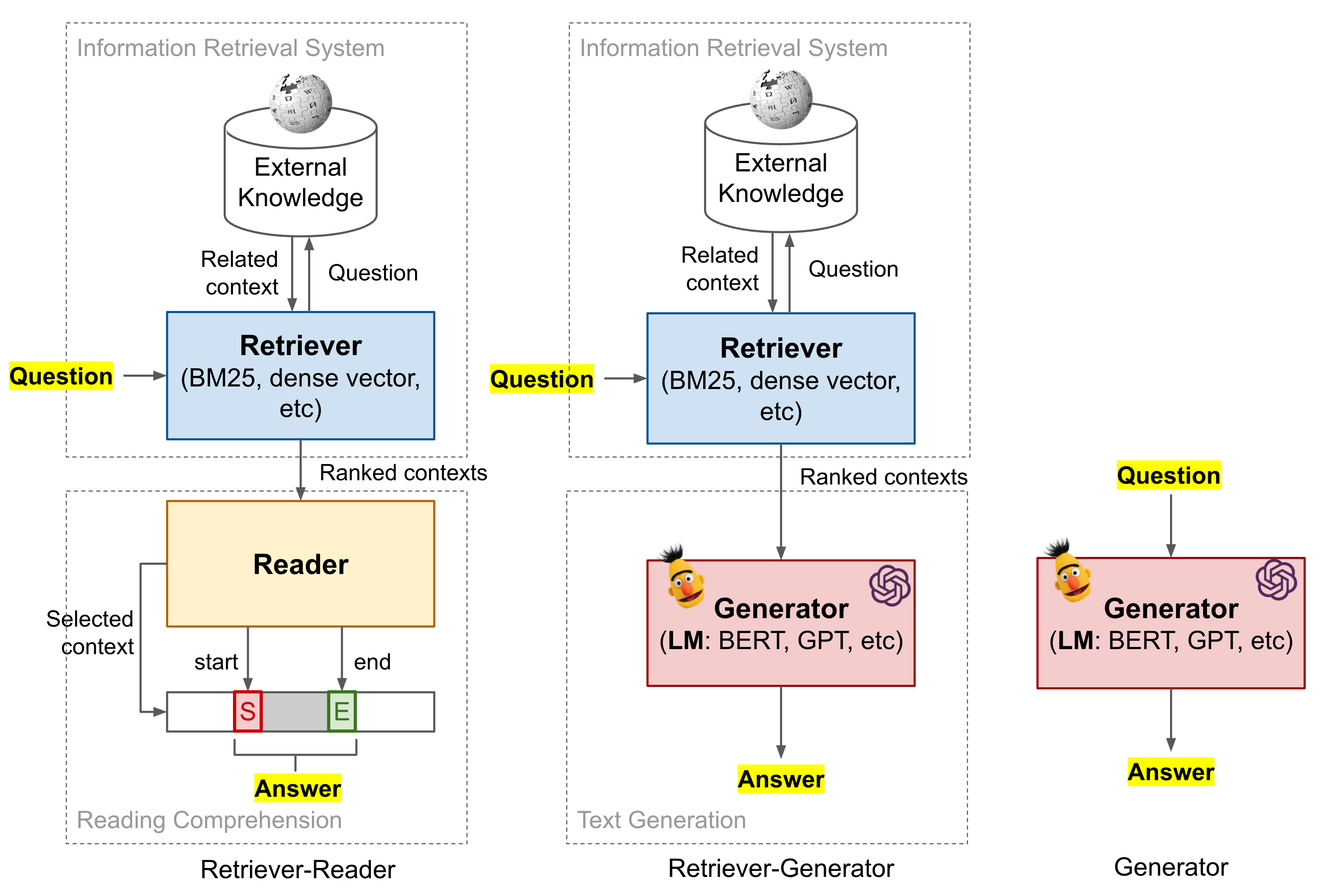
The OIG Dataset

Papers With Code Machine Learning Papers and Code Free Resource
XQuAD Dataset Papers With Code
How to Answer Questions with Machine Learning

Snorkel AI researchers present 18 papers at NeurIPS 2023
An Introduction to Papers With Code: What It is And How to Use It

The OIG Dataset
.png)
How to train YOLOv8 on a custom Dataset — Picsellia

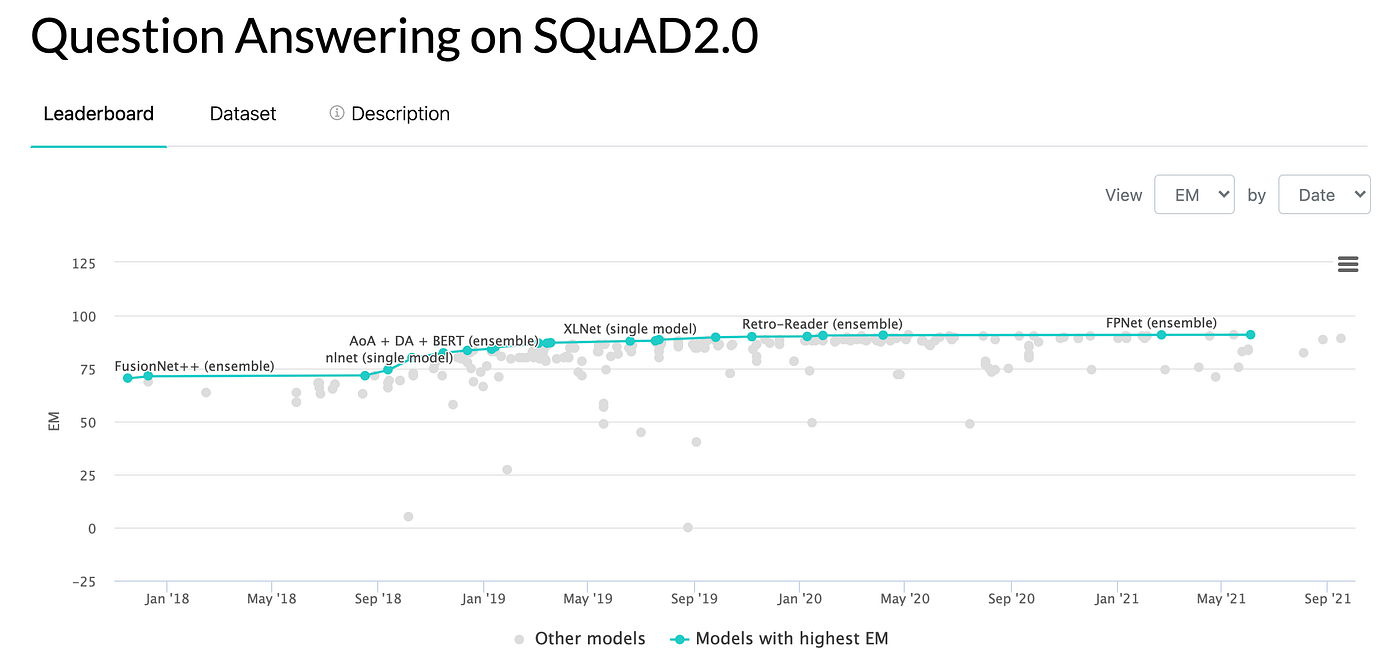
iFLYTEK & HIT Reading Comprehension Model Betters Humans, Tops
Recomendado para você
-
 Gas Turbine Interview Questions and Answers - Power Plant22 abril 2025
Gas Turbine Interview Questions and Answers - Power Plant22 abril 2025 -
 Pin on Engineering22 abril 2025
Pin on Engineering22 abril 2025 -
 SOLUTION: Mcqs preparation for engineering competitive exams pdfdrive - Studypool22 abril 2025
SOLUTION: Mcqs preparation for engineering competitive exams pdfdrive - Studypool22 abril 2025 -
 Dk & Eng - Engine - Page 1 - Witherbys22 abril 2025
Dk & Eng - Engine - Page 1 - Witherbys22 abril 2025 -
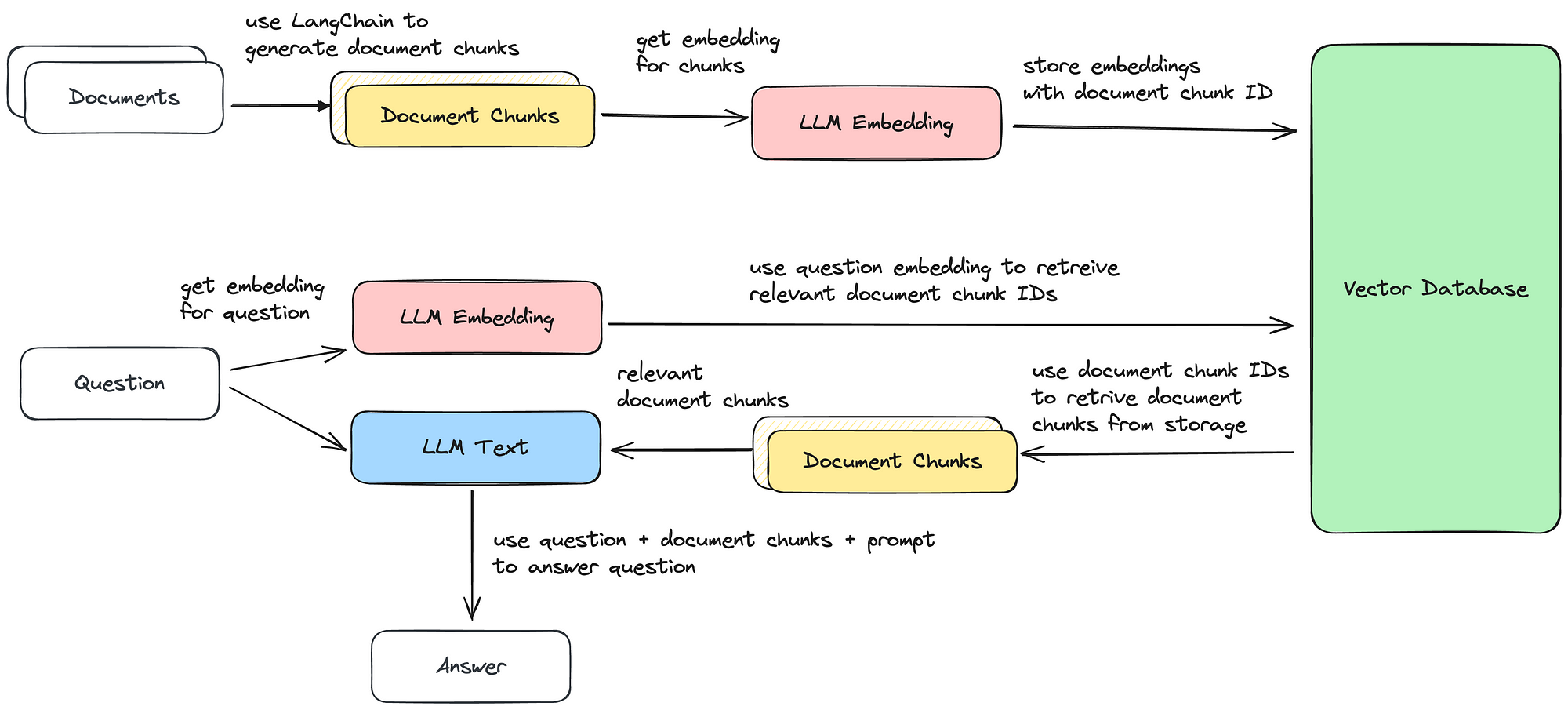 Generative AI - Document Retrieval and Question Answering with LLMs, by Sascha Heyer, Google Cloud - Community22 abril 2025
Generative AI - Document Retrieval and Question Answering with LLMs, by Sascha Heyer, Google Cloud - Community22 abril 2025 -
 ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score22 abril 2025
ART101 - Courtney Rowles - Chapter 1 Worksheet.pdf - 1 Chapter pter The Automobile Courtney Rowles Name March 10 Date Mr. Lindsay Instructor Score22 abril 2025 -
 Question and answers Mechanical Engg Simple Notes ,Solved problems and Videos22 abril 2025
Question and answers Mechanical Engg Simple Notes ,Solved problems and Videos22 abril 2025 -
 NODE.JS Interview Questions & Answers - CodeWithCurious22 abril 2025
NODE.JS Interview Questions & Answers - CodeWithCurious22 abril 2025 -
 1. In an ideal engine, as can be seen form the diagram the entire22 abril 2025
1. In an ideal engine, as can be seen form the diagram the entire22 abril 2025 -
 Show Me Tell Me Questions 202422 abril 2025
Show Me Tell Me Questions 202422 abril 2025
você pode gostar
-
Moria the Khazad dûm - - 3D Warehouse22 abril 2025
-
 Arquivo de corte topo de bolo mestre cuca22 abril 2025
Arquivo de corte topo de bolo mestre cuca22 abril 2025 -
 Gallery - BR Management22 abril 2025
Gallery - BR Management22 abril 2025 -
 Gameshark 2 v1.3 for PS2 – Snyder Repair Services22 abril 2025
Gameshark 2 v1.3 for PS2 – Snyder Repair Services22 abril 2025 -
 fnf custom mod shackled Project by Smartly Mammal22 abril 2025
fnf custom mod shackled Project by Smartly Mammal22 abril 2025 -
Tails exe photo 💜22 abril 2025
-
 The Welsh IT sales worker who's the strongest woman in the world22 abril 2025
The Welsh IT sales worker who's the strongest woman in the world22 abril 2025 -
 Álex Pastrana, un ingeniero en Edén y Élite: Lo dejé todo22 abril 2025
Álex Pastrana, un ingeniero en Edén y Élite: Lo dejé todo22 abril 2025 -
 Cómo conseguir personajes totalmente gratis sin hacks!(con Subway22 abril 2025
Cómo conseguir personajes totalmente gratis sin hacks!(con Subway22 abril 2025 -
 Yuckquee Programming/Coding Laptop Skin for HP,Asus,Acer,Dell22 abril 2025
Yuckquee Programming/Coding Laptop Skin for HP,Asus,Acer,Dell22 abril 2025
